Система плагинов: как завезти нейронные сети в dotnet
Эта статья о том как запихать нейронную сеть в каждый компьютер или смартфон используя dotnet, С++, плагины и немного магии!
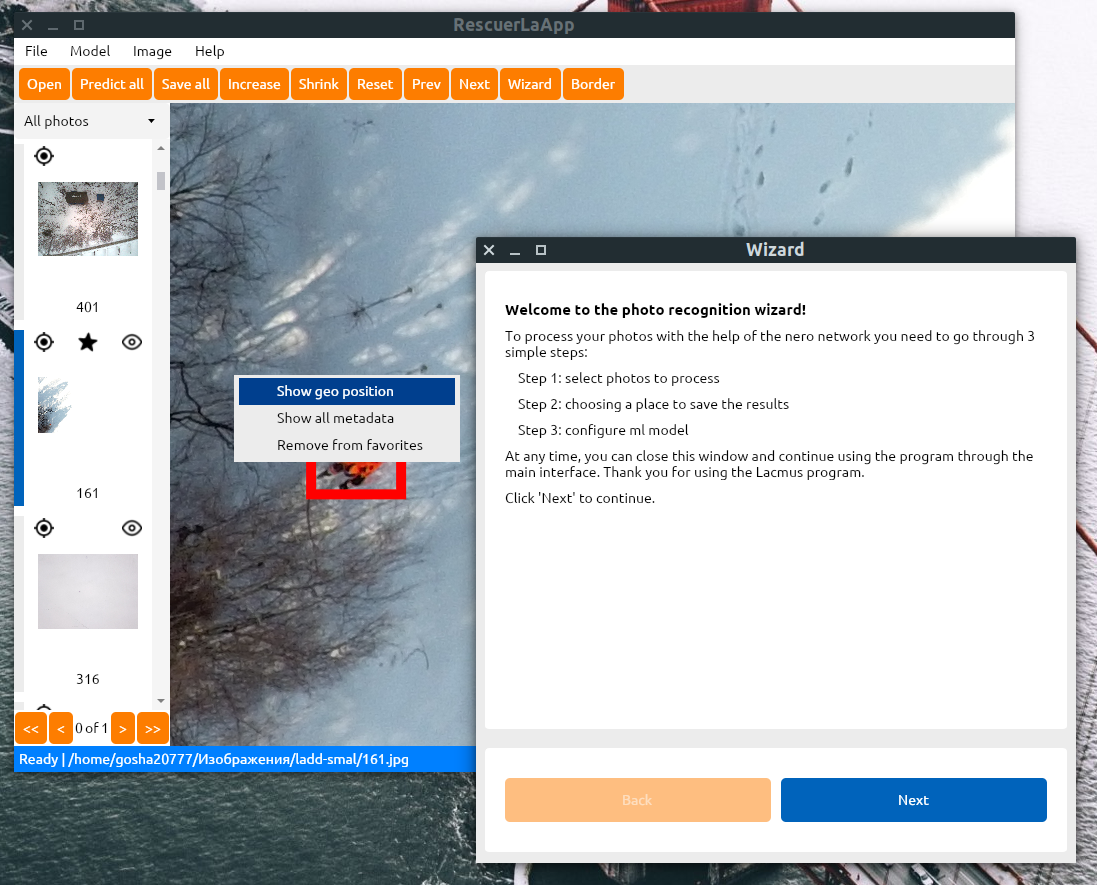
Вот уже несколько лет я занимаюсь тем что в свободное время веду Open Source проект Lacmus цель которого помогать добровольным поисково-спасательным отрядом и мчс находить пропавших в лесу людей с помощью компьютерного зрения и нейронных сетей. Подробнее об этом можно почитать в нашей статье на Хабре или посмотреть документальны ролик.
Предыстория
Одним из наших продуктов является кросс платформенное приложение написанное на dotnet core и AvaloniaUI работающее на Windows / Linux / MacOS. Наша главная цель обеспечить возможность запуска и работы приложения на максимальном количестве устройств с максимально возможной производительностью - ведь от скорости обработки данных может зависть жизнь пропавшего бедолаги. Во многом по этому в качестве фреймверка отрисовки интерфейса был выбран Avalonia UI - ведь он быстрый, требует мало ресурсов и способен запускаться на любых устройствах: от Windows компьютеров до RaspberyPI с Arch Linux на борту. А еще на нем можно рисовать красивый UI.
Приложение состоит из 2 частей:
- GUI фронтенда
- Бекенда запускающего нейронные сети
О GUI я немного рассказывал ранее, но как быть с нейрончками?
API v1: как это работало раньше?
Решение было найдено довольно быстро - docker!
Docker - ПО, позволяющее запускать процессы в изолированном от основной ОС окружении на базе специально созданных образов. Таким образом мы избавляем пользователя от необходимости установки дополнительных драйверов, сборке пакетов, настройки окружения необходимого для запуска и работы нейронной сети. Пользователю достаточно иметь только Docker все остальное программа сделает за пользователя. Подробнее о docker можно почитать в моей предыдущей статье в разделе “Погружение в контейнер”.
Итак…
- Для запуска нейронной сети создавался контейнер, внутри которого был маленький http web server (написаный на python) умеющий обрабатывать картинку с помощью нейронной сети и предоставляющий REST API для взаимодействия. Там же, в контейнере находились все необходимые для работы драйвера и библиотеки.
- Контейнер загружался на публичный реестр Docker Hub и становился доступным для скачивания.
- GUI приложение содержало в себе клиент к docker который мог манипулировать контейнерами: запускать, скачивать, удалять…
- После запуска контейнера с нейронной сетью приложение узнавало его порт на localhost-е и начинала отправлять на локальный сервер http запросы с картинками, а в ответ получала результаты работы нейронной сети.
У такого подхода есть очевидные достоинства:
- Конечно это простота разработки и внедрения. Закинул все что надо в контейнер, вбил заветные
docker buildиdocker pullв терминале и вот твоя новая модель уже доступна всем пользователям. - Отвязанность от языка программирования и ML фреймверков. В докер можно закинуть все что угодно. Ты кодишь на С++ и нависал инференс своего алгоритма на нем - не вопрос. Закодил сервер на python - пожалуйста. NodeJs + TensorflowJS на худой конец? даже эта штука заведется)
- Также docker regestry - удобный способ хранения и версионирования контейнеров.
Но за эти удобства приходится платить:
- Производительность в Windows/OSX. Докер хорошо и нативно работает только на Linux. Тут все процессы запускаются без виртуализации, а значит нет просадок по производительности. Но к сожалению на других ОС это не так: там докер это обычная виртуальная машина с linux, на которой уже запущен докер со всеми вытекающими. Даже на близких к linux - OSX и BSD системах нативной поддержки docker нет и это тоже виртуалка.
- Второй пункт вытекает из первого. На всех системах кроме linux невозможно (или очень сложно) пробросить в docker периферийные устройства - будь то USB с тензорным сопроцессором (intel mividius, google edge tpu) или PCI-E устройство.
- Относительная сложность установки docker на не Linux системы. Это в linux есть пакетные менеджеры и можно прописать docker в зависимости своего приложения. При установке пакетный менеджер сам скачает и установит нужные зависимости. А вот в windows и MacOS по умолчанию этого не предусмотрено => задача установки docker ложится на плечи пользователя, что может вызвать трудности у некоторых людей.
- Размер образов. Помимо операционной системы, docker образ содержит в себе все драйвера и библиотеки и веса модели. Поэтому вес докер образа мог быть и 2 и 4 гб. Это конечно меньшее зло но все-же.
- ARM. ARM шагает по планете, а у докер пока очень слабая поддержка данной архитектуры.
По началу большинство наших пользователей использовали linux и проблем не было (золотое время). Но постепенно, с ростом популярности ПО к нам стали приходить люди с Windows или OSX. И если на машине на Linux обработка 1 изображения занимает 1-2 с, но такой же машине на Windows это же время составляет уже долгие 10 c (!). Да да, виртуализация на Windows и MacOs - полный отстой… До KVM им как до луны… Все это подтолкнуло меня на мысль что дальше так продолжаться не может и миру нужны новые герои…
API v2: Главное - это плагины!
Очевидно что необходимо отказываться от докера - запускать весь код нативно. Но как? Как обеспечить кросс-платформенное выполнение разного кода на разных платформах? Как дать возможность разработчикам использовать разные фреймверки и технологии? Как избавить простого пользователя от установки дополнительных драйверов? Сейчас разберемся!
Будем двигаться снизу вверх. Начнем с низкоуровневых, платформозависимых аспектов и закончим верхнеуровневым кросс-платформенным api.
0. Железо и операционные системы

Несмотря на то что мир компьютерной техники стал более-менее стандартизованным по сравнению с тем что было 15-20 лет назад - количество платформ все еще остается довольно большим. Давайте рассмотрим современные актуальные платформы под которые и будем писать свой нативный C++ код.
- Архитектуры процессора:
- x86_64
- Arm
- Операционные системы:
- Linux
- Widows
- MacOS
- Android
- IOS
- Вычислительные устройства:
- CPU
- GPU
- Nvidia Cuda GPU
- AMD GPU
- Intel GPU
- Сопроцессоры
- Google Edge TPU
- Intel Movidius NPU
С помощью нехитрых математических расчетов и здравого смысла можно легко актуализировать количество поддерживаемых нужных нам платформ:
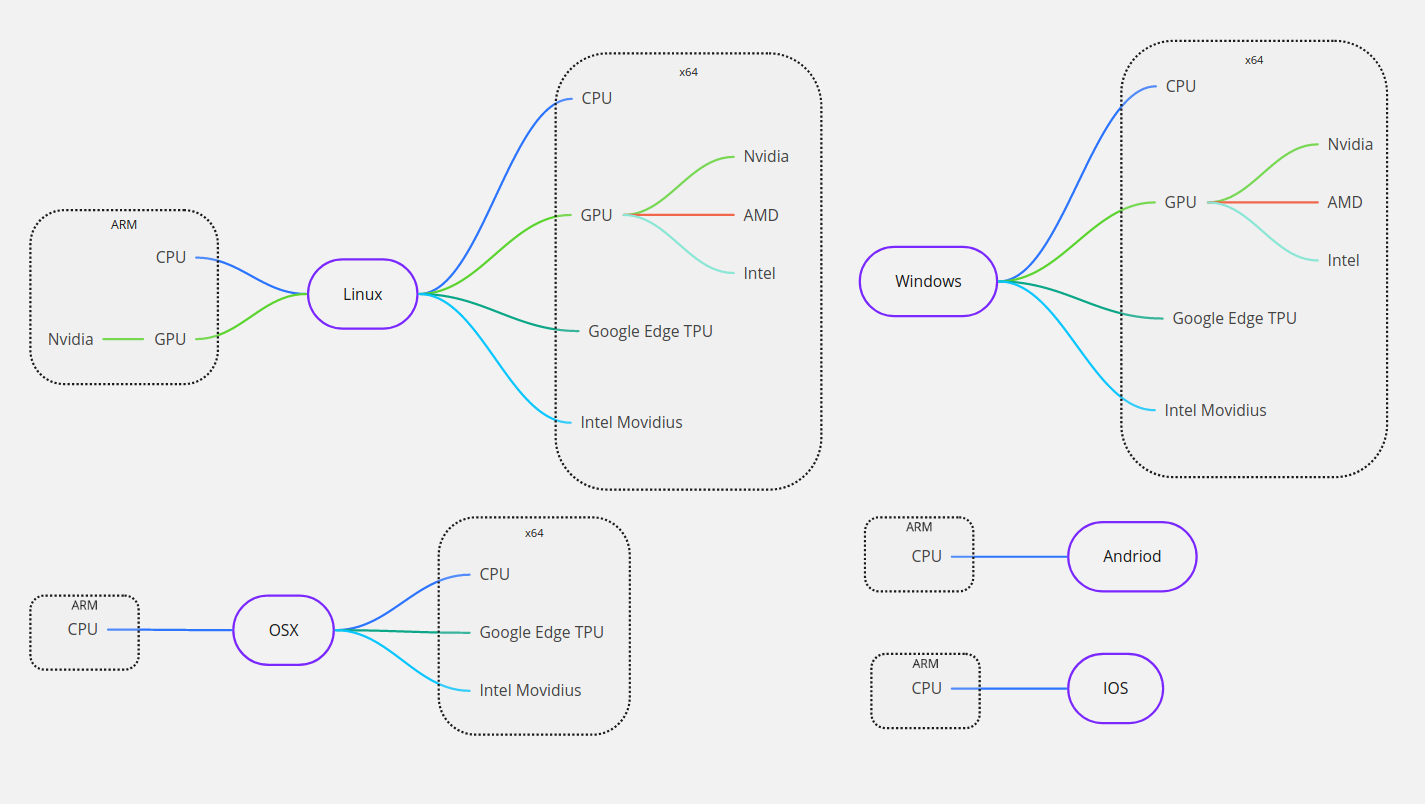
Как видно из схемы различных конфигураций платформ довольно много. По этому для уменьшения количества информации в этой статье мы рассмотрим только 64-bit системы и только CPU и GPU. Ну что же, давайте карабкаться выше.
1. Драйвера и бекенды фреймверки нейронных сетей.
И так у нас есть конечные железяки на которых запущена та или иная ОС. Чтобы заставить железку производить какие-либо вычисления нужно научиться общаться с железкой на понятном ей языке. Этим и занимаются драйверы и ml-бекенды.
- Драйвер - это программа которая обеспечивает низкоуровневый доступ к железяке. Если драйвер не установлен - то железяка не будет доступна в системе.
- ML-бекенд - это набор низкоуровневых библиотек предоставляющий набор базовых математических операций на железяке или группе железок.
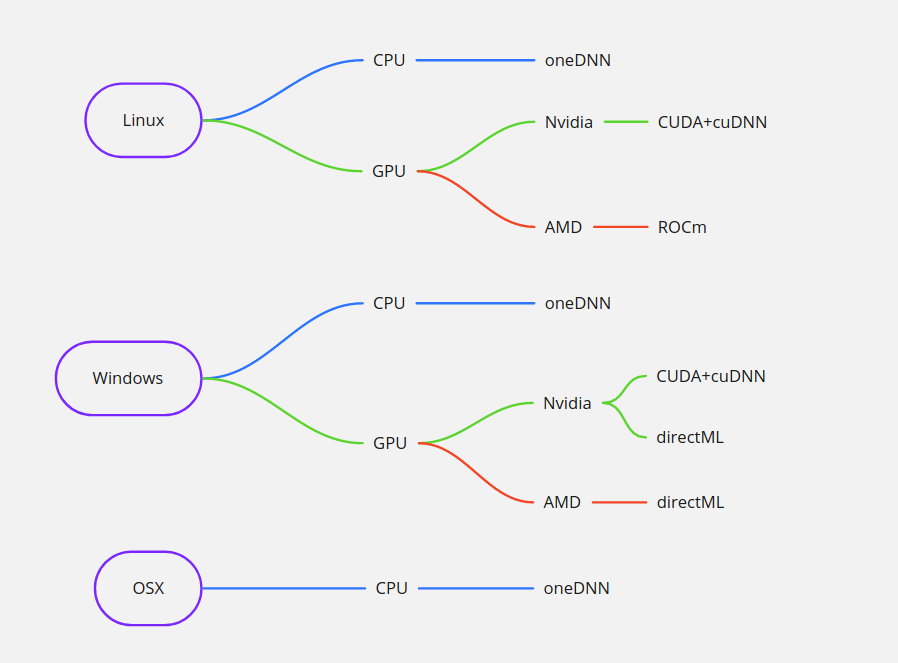
Бекендов может быть много и они могут быть совместимы с разным оборудованием. Так например, выполнять расчеты на процессорах можно с помощью MKL-DNN и oneDNN, на GPU от зеленых - CUDA+cuDNN и directML, на красных GPU - ngraph, ROCm и directML. Очевидно что выбор бекенда прямым образом влияет на производительность и скорость вычислений. Бекенды могут быть как открытыми так и проприетарными. Вторым фактором производительности является операционная система.
Самым быстрым на данный момент набор CUDA+cuDNN+Linux. Именно по этому для обучения нейронных сетей используются GPU от Nvidia и Linux сервера.
Протестировав производительность и выбрав оптимальные я пришел вот к таким результатам:
2. Высокоуровневые ML фреймверки и библиотеки
За сравнительно малое время существования ml как отрасли возникло и умерло много фреймверков. На данный момент актуальными и самыми популярными фреймверками глубокого обучения являются PyTorch и Tensorflow. У каждого из них есть свои фанаты и противники.
Помимо фреймверков для разработки нейронных сетей (PyTorch и Tensorflow) есть библиотеки для инференса (запуска) уже готовых, обученыx моделей. Одни из них является OnnxRuntime. Его разрабатывает и поддерживает Microsoft.
Каждый фреймверк или библиотека имеет свое C++ API и его биндинги в Python.
Для того чтобы иметь возможность использовать фреймверк в шаровом коде мне необходимо было пробросить C++ API в шарпы. …И собрать нативные библиотеки этих фреймверков для всех платформ и бекендов.
Так как я являюсь поклонником Tensorflow то я реализовал поддержку этого фреймверка. И OnnxRuntime - но тут за меня постарался Microsoft.
Сборка библиотек
Итого у меня получился вот такой вот список нативных библиотек:
- Linux-x64:
- tensorflow
- cpu (oneDnn)
- gpu (cuDnn)
- gpu (rocm)
- onnxRuntime
- cpu (oneDnn + openMP) - спасибо microsoft
- gpu (cuDnn) - спасибо microsoft
- gpu (rocm)
- tensorflow
- Windows-x64
- tensorflow
- cpu (oneDnn)
- gpu (cuDnn)
- gpu (directML)
- onnxRuntime
- cpu (oneDnn + openMP) - спасибо microsoft
- gpu (cuDnn) - спасибо microsoft
- gpu (directML) - спасибо microsoft
- tensorflow
- OSX-x64
- tensorflow
- cpu (oneDnn)
- onnxRuntime
- cpu (oneDnn + openMP) - спасибо microsoft
- tensorflow
Примечание - сборка tensorflow это довольно трудоемкий процесс и по сложности он сопоставим наверно со сборкой linux из source кода. Только компиляция занимает 5-8 часов. Самым сложным была сборка под windows с ее отвратительным microsoft C++ компилятором… OnnxRuntime собирается легче и быстрее. В общей сложности на сборку и фикс ошибок всего у меня ушли почти все новогодние праздники)))

Интеграция в C#
OnnxRuntime и так имеет официальное C# API по этому тут не было никаких проблем. Что касается Tensorflow то тут есть 2 проекта - умерший TensorflowSharp и активно развивающийся Tensorflow.NET. Ни с тем ни с другим из коробки у меня модель не заработала. Но Tensorflow.NET оказался более хорошим, разработчики быстро ответили на мое issue я завез им Pull Request и у меня все взлетело! (ура).
3. Система плагинов
Для того чтобы пользователи могли устанавливать различные версии ML моделей а также чтобы другие разработчики могли создавать и подключать свои модели я запилил систему плагинов. Тут будет немного кода и описание того как это работает.
Интерфейс
Для того чтобы было возможно запускать и управлять плагинами у них должен быть единый интерфейс - IObjectDetectionPlugin:
using System;
using System.Collections;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
using LacmusBasePlugin.Enums;
namespace LacmusBasePlugin
{
public interface IObjectDetectionPlugin
{
public string Name { get; }
public string Description { get; }
public string Author { get; }
public string Url { get; }
public Version Version { get; }
public InferenceType InferenceType { get; }
public HashSet<OperatingSystem> OperatingSystems { get; }
public IObjectDetectionModel LoadModel();
}
}Он предоставляет программе информацию о плагине и позволяет создать ml модель.
Давайте пробежимся по полям.
Version - это структура которая хранит версию плагина:
namespace LacmusBasePlugin
{
public readonly struct Version
{
public Version(int api, int major, int minor)
{
Api = api;
Major = major;
Minor = minor;
}
public int Api { get; }
public int Major { get; }
public int Minor { get; }
public override string ToString()
{
return $"{Api}.{Major}.{Minor}";
}
}
}InferenceType - тип устройства на котором будет производиться инференс:
namespace LacmusBasePlugin.Enums
{
public enum InferenceType
{
Cpu = 10,
CudaGpu = 20,
AmdGpu = 21,
AnyGpu = 22,
GoogleTpu = 30
}
}OperatingSystems - набор операционных систем для которых доступен плагин:
namespace LacmusBasePlugin
{
public enum OperatingSystem
{
WindowsAmd64 = 10,
WindowsArm = 11,
LinuxAmd64 = 20,
LinuxArm = 21,
AndroidArm = 22,
OsxAmd64 = 30,
OsxArm = 31,
IosArm = 32
}
}Сама модель представлена интерфейсом IObjectDetectionModel:
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
namespace LacmusBasePlugin
{
public interface IObjectDetectionModel : IDisposable
{
public IEnumerable<IObject> Infer(string imagePath, int width, int height);
public Task<IEnumerable<IObject>> InferAsync(string imagePath, int width, int height);
}
}Метод Infer реализует инференс нейронной сети. На вход он принимает imagePath - путь до картинки и ее размеры в пикселях width и height. В качестве результата он отдает коллекцию распознанных объектов IObject:
namespace LacmusBasePlugin
{
public interface IObject
{
public string Label { get; set; }
public float Score { get; set; }
public int XMin { get; set; }
public int XMax { get; set; }
public int YMin { get; set; }
public int YMax { get; set; }
public int Width => XMax - XMin;
public int Height => YMax - YMin;
}
}Пишем свой плагин!
В данном случае будем рассматривать пример с использованием Tensoeflow cpu (oneDnn).
Первым делом создаем проект с нашим плагином LacmusRetinanetPlugin.csproj и добавим туда ссылку на проект с базовыми интерфейсами:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netcoreapp3.1</TargetFramework>
<AssemblyName>LacmusRetinanetPlugin</AssemblyName>
<RootNamespace>LacmusRetinanetPlugin</RootNamespace>
</PropertyGroup>
<ItemGroup>
<ProjectReference Include="..\LacmusBasePlugin\LacmusBasePlugin.csproj">
<Private>false</Private>
<ExcludeAssets>runtime</ExcludeAssets>
</ProjectReference>
</ItemGroup>
</Project>Важно добавить свойства <Private>false</Private> и <ExcludeAssets>runtime</ExcludeAssets> чтобы плагин был доступен для загрузки и вместо с ним поставлялись все нативные библиотеки для различный ОС.
Далее нам нужно установить C# биндинги для работы с tensorflow:
Install-Package TensorFlow.NETА также нативную библиотеку с нужной нам платформой
Install-Package SciSharp.TensorFlow.Redist -Version 2.3.1Для CUDA+cuDNN надо использовать Install-Package SciSharp.TensorFlow.Redist-Windows-GPU и Install-Package SciSharp.TensorFlow.Redist-Windows-GPU. Для DirectML - Install-Package SciSharp.TensorFlow.Redist-Windows-DirectML для rocm - Install-Package SciSharp.TensorFlow.Redist-Linux-Rocm и т д. С OnnxRuntime история повторяется. Список доступных библиотек можно будет посмотреть в нашем репозитории.
Важно понимать что одновременно можно использовать только один набор нативных библиотек. То есть установить в один плагин и tf c oneDnn и tf с Cuda не получится (я надеюсь понятно почему). Для каждого типа инференса нужно будет собрать отдельный плагин.
И так для нормальной работы плагина нам необходимо имплементировать 3 интерфейса IObjectDetectionPlugin, IObjectDetectionModel и IObject.
Код класса Plugin.cs:
using System.Collections.Generic;
using LacmusBasePlugin;
using LacmusBasePlugin.Enums;
namespace LacmusRetinanetPlugin
{
public class Plugin : IObjectDetectionPlugin
{
public string Name => "Lacmus Retinanet";
public string Description => "Resnet50+deepFPN neural network";
public string Author => "Lacmus Foundation";
public string Url => "https://github.com/lacmus-foundation/lacmus";
public Version Version => new Version(api: 2, major: 1, minor: 0);
public InferenceType InferenceType => InferenceType.Cpu;
public HashSet<OperatingSystem> OperatingSystems => new HashSet<OperatingSystem>()
{
OperatingSystem.LinuxAmd64,
OperatingSystem.WindowsAmd64,
OperatingSystem.OsxAmd64
};
public IObjectDetectionModel LoadModel()
{
return new Model();
}
}
}Код класса Model.cs:
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Reflection;
using System.Threading.Tasks;
using NumSharp;
using LacmusBasePlugin;
using Tensorflow;
using static Tensorflow.Binding;
namespace LacmusRetinanetPlugin
{
public class Model : IObjectDetectionModel
{
private const string _pbFile = "LacmusRetinanetPlugin.ModelWeights.frozen_inference_graph.pb";
private const float _minScore = 0.5f;
private const string _inputTensorName = "input_1";
private const string _outputBboxTensorName = "Identity";
private const string _outputScoreTensorName = "Identity_1";
private const string _outputLabelsTensorName = "Identity_2";
private Graph _graph;
private Session _session;
public Model()
{
tf.compat.v1.disable_eager_execution();
_graph = new Graph();
//try to load pb graph from embedded resources
var assembly = Assembly.GetExecutingAssembly();
using (var stream = assembly.GetManifestResourceStream(_pbFile))
{
using (var ms = new MemoryStream())
{
stream?.CopyTo(ms);
var isOk = _graph.Import(ms.ToArray());
if(!isOk || _graph.ToArray().Length == 0)
throw new Exception("unable to import graph");
_session = tf.Session(_graph);
}
}
}
public IEnumerable<IObject> Infer(string imagePath, int width, int height)
{
var startTime = DateTime.Now;
var imgArr = PreprocessImage(imagePath, width, height, out var scale);
Console.WriteLine("Preprocess image at {0} s", DateTime.Now - startTime);
_graph = _graph.as_default();
Tensor inputTensor = _graph.OperationByName(_inputTensorName);
Tensor tensorBoxes = _graph.OperationByName(_outputBboxTensorName);
Tensor tensorScores = _graph.OperationByName(_outputScoreTensorName);
Tensor tensorLabels = _graph.OperationByName(_outputLabelsTensorName);
Tensor[] outTensorArr = new Tensor[] { tensorBoxes, tensorScores, tensorLabels };
var results = _session.run(outTensorArr, new FeedItem(inputTensor, imgArr));
return FilterDetections(results, scale);
}
public async Task<IEnumerable<IObject>> InferAsync(string imagePath, int width, int height)
{
return await Task.Run(() => Infer(imagePath, width, height));
}
public void Dispose()
{
_session.Dispose();
_graph.Dispose();
GC.Collect();
}
private NDArray PreprocessImage(string imagePath, int width, int height, out float scale)
{
scale = ComputeImageScale(width, height);
var size = np.array((int)(height * scale), (int)(width * scale));
var fileReader = tf.io.read_file(imagePath, "file_reader");
var decodeJpeg = tf.image.decode_jpeg(fileReader, channels: 3, name: "DecodeJpeg", dct_method: "INTEGER_ACCURATE");
var casted = tf.cast(decodeJpeg, TF_DataType.TF_FLOAT);
var castedBgr = tf.reverse(casted, axis: np.array(-1));
var std = tf.constant(np.array(103.939f, 116.779f, 123.68f));
var castedBgrNormalized = tf.sub(castedBgr, std);
var dimsExpander = tf.expand_dims(castedBgrNormalized, 0);
var resizeJpeg = tf.image.resize_bilinear(dimsExpander, size, half_pixel_centers: true);
return resizeJpeg.eval();
}
private float ComputeImageScale(int width, int height, int minSide = 2100, int maxSide = 2100)
{
var smallestSide = Math.Min(width, height);
var scale = minSide / (float)smallestSide;
var largestSide = Math.Max(width, height);
if (largestSide * scale > maxSide)
{
scale = maxSide / (float)largestSide;
}
return scale;
}
private IEnumerable<IObject> FilterDetections(NDArray[] resultArr, float scale)
{
var scores = resultArr[1].AsIterator<float>();
var boxes = resultArr[0].GetData<float>();
var id = np.squeeze(resultArr[2]).GetData<float>();
var filteredObjects = new List<IObject>();
for (int i = 0; i < scores.size; i++)
{
float score = scores.MoveNext();
if (score > _minScore)
{
float xMin = boxes[i * 4] / scale;
float yMin = boxes[i * 4 + 1] / scale;
float xMax = boxes[i * 4 + 2] / scale;
float yMax = boxes[i * 4 + 3] / scale;
string label = "Pedestrian";
var obj = new DetectedObject
{
Label = label,
Score = score,
XMin = (int)xMin,
XMax = (int)xMax,
YMin = (int)yMin,
YMax = (int)yMax
};
filteredObjects.add(obj);
}
}
return filteredObjects;
}
}
}И наконец DetectedObject.cs:
using LacmusBasePlugin;
namespace LacmusRetinanetPlugin
{
public class DetectedObject : IObject
{
public string Label { get; set; }
public float Score { get; set; }
public int XMin { get; set; }
public int XMax { get; set; }
public int YMin { get; set; }
public int YMax { get; set; }
}
}После сборки плагина мы получим вот такую структуру:
├── Google.Protobuf.dll
├── LacmusRetinanetPlugin.deps.json
├── LacmusRetinanetPlugin.dll
├── LacmusRetinanetPlugin.pdb
├── MethodBoundaryAspect.dll
├── Microsoft.Extensions.DependencyInjection.Abstractions.dll
├── Microsoft.Extensions.DependencyInjection.dll
├── NumSharp.Lite.dll
├── Protobuf.Text.dll
├── runtimes
│ ├── linux-x64
│ │ └── native
│ │ ├── libtensorflow_framework.so.2
│ │ └── libtensorflow.so
│ ├── osx-x64
│ │ └── native
│ │ ├── libtensorflow.dylib
│ │ └── libtensorflow_framework.2.dylib
│ └── win-x64
│ └── native
│ └── tensorflow.dll
├── Serilog.dll
├── Serilog.Sinks.Console.dll
└── TensorFlow.NET.dllКак видно все наши нативные библиотеки и их зависимости включены в сборку и пользователю не придется ничего устанавливать
Веса модели frozen_inference_graph.pb тут были добавлены в проект как EmbeddedResource. Таким образом мы зашиваем их в готовую библиотеку и скрываем от пользователя. Чтобы получить их придется заняться реверс инженерингом и изрядно попотеть. Б - безопасность наше все.
После успешной сборки плагин можно протестировать с помощью консольной утилиты которая находится в том же репозитории.
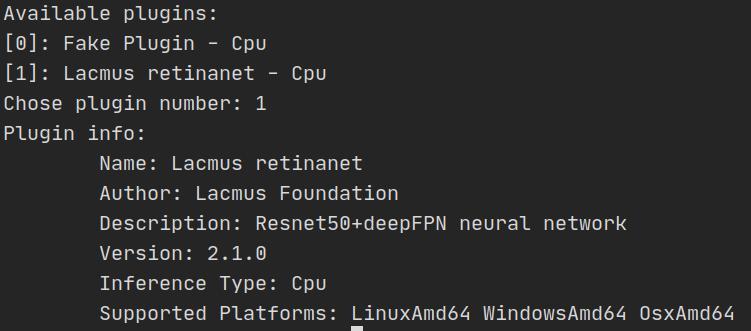
Что дальше?
Плагины надо как то доставлять конечным пользователям. Тут ничего не поделать придется писать код реализующий реестр плагинов и предоставляющий API для доступа к ним. Скорее всего это будет что-то по типу docker реестра - open source сервер на dotnet. Мы сможем поднять его на наших серверах и будет что то вроде “официального” реестра. Открытый код же позволит другим разработчикам поднимать свои реплики у себя или к нам в рестр, а пользователь используя функционал программы сможет добавить себе тот или иной реестр и получить плагины из желаемого источника. Как говориться свобода и демократия.
Также есть мысль подобным образом сделать биндинг python и C# кода. Тогда разработчик сможет писать плагины на родном ему python. По задумке разработчик должен будет написать python скрипт реализующий необходимый интерфейс, дать команду сборщику и запустить процесс сборки. Сборщик генерирует C# код, установит необходимые библиотеки и запустит процесс компиляции. После компиляции появится готовый плагин, в папке native окажутся интерпретатор питона виртуальное окружение со всеми необходимыми пакетами, чтобы конечному пользователю не пришлось ничего устанавливать. А C# код вызывал бы интерпретатор python и получал бы от него результат как то так:
public IEnumerable<IObject> Infer(string imagePath, int width, int height)
{
using (Py.GenerateIL())
{
dynamic plugin = Py.Import("lacmus_plugin");
dynamic predictions = plugin.infer(imagePath, width, height);
foreach(pred in predictions)
{
...
}
}
GC.Collect();
...
}Вот она дружба народов!

З.Ы.
Ыыыы. Што то сложна вышло. Надеюсь, ваш мозг взорвался и вы дожили до конца) Надеюсь, было интересно. Спасибо за внимание.
Полезные ссылки
- Исходный код проекта с плагинами - да пока тут нет внятного описания. Скоро появися)
- Исходный код GUI приложения
- Исходный код нейронной сети
- Разница в декодировании изображений между opencv и tf
- Ссылка на наш чат в телеге - заходите у нас лампово